
12/20090
Hadoop

Népnevelő sorozatunk mai részében a Hadoop-ról beszélünk.
A Google File System-et, vagy leánykori nevén BigFiles rendszert Larry Page és Sergey Brin fejlesztette ki még a google éra hajnalán. A fájlok 64 megás darabokban tárolódnak, amelyek csak nagyon ritkán íródnak felül (legalábbis ez a koncepció).
Arra tervezték, hogy olcsó gépeken fusson, ezzel szükségessé téve a hibák okozta adatvesztés elleni robosztusabb védelmet.
A master-slave architektúrába szervezett chunkserverek vezérlését egy master csomópont vezényli, amely a chunkservereken tárolt adategységekhez kötődő fájlokról, és az adategységeken műveleteket végző processzekről tárol metaadatokat illetve információt. Az adatokhoz hozzáférő programok elsőként a master egységhez fordulnak, akitől megkapják a kívánt adatcsomag helyét (ha az adatot tároló node-ot éppen nem foglalja le azt más process), majd az adatot közvetlenül a chunkserverről töltik le.
A BigTable egy 2004-től fejlesztett, többek közt GFS alapokra épülő gyors, és végletekig (több száz, ezer csomópontos, petaByte léptékű rendszerek) skálázható DBMS. Azonban ne hagyományos DBMS-ként gondoljunk rá, hanem "ritka, elosztott, több dimenziós rendezett indexként", amely mind a sor mind az oszlop alapú adatbázisok karakterisztikájával rendelkezik. Minden tábla több dimenzióadatot tárol, amelyek egyike az idődimenzió, így lehetővé válik a verziókövetés.
Mindezekre rátelepszik a MapReduce keretrendszer, amelyet szintén (ki más?) Google testvér fejlesztett nekünk. Nagy adathalmazok párhuzamos feldolgozásában segítségünkre lehet, és deklaratív SQL használata helyett - a sok programozó számára otthonosabb - funkcionális programozási nyelvekbe illeszkedik C++, C#, Erlang, Java, Python, Ruby, F# és R programkönytárai segítségével. A "MapReduce enabled" program két fő szakasza az inputot kisebb egységekre bontó, majd azokat a szolga node-oknak feladatként (akár rekurzívan) kiosztó MAP; illetve a masteren futó, a szolga csomópontoktól kapott válaszokat a kívánt kimeneti formába ötvöző REDUCE.
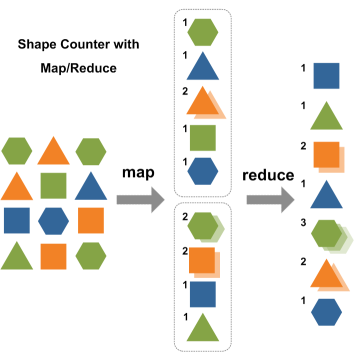
Map reduce működése
Az imént részletezett technológiák nagyon jónak és hasznosnak tűnnek. A Google-nak. Ugyanis a GFS és a BigTable nem publikusan hozzáférhető fejlesztések. De pánikra semmi okunk, hiszen nagyszerű programozók az iménti helyzet felett érzett frusztrációjukban buzgón lemásolták és OpenSource formában szabadon hozzáférhetővé tették a funkcionalitásban állítólag feketehalálig (vagy minek nevezzem *nix alatt) hasonlóan pedikűrözött applikációikat.
Az egyik ilyen a Hadoop.
A Hadoopot az Apache foundation vette gondozásába, működése hajaz a fentebb GFS-nél leírtakra. A Hadoopra épülő MapReduce motor egy Job Tracker és sok Task Tracker node-ból áll. A Job Tracker az adatlokalitást szem előtt tartva osztja szét a workloadot a Task Tracker csomópontok között, és ha az adatot tároló Task Tracker node épp elfoglalt, egy hozzá közel eső node-ot jelöl ki az adat feldolgozására. Task Tracker hiba esetén csak a hozzá rendelt, Job Tracker hiba esetén a teljes feldolgozás alatt lévő job elveszlik. A Hadoop-ot az Apache számos egyéb szolgáltatással szervírozza, az applikációs stack az alábbi ábrán vehető szemügyre.
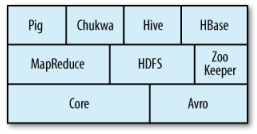
Hadoop stack
Pig:
Nagyon nagy adatállományok kezeléséhez használható adatfolyamleíró és végrehajtó nyelv
HBase:
Elosztott, oszlop alapú adatbázis, amely a HDFS-t használja storage rétegként. Támogatja a kötegelt MapReduce és az ad-hoc lekérdezéseket is
ZooKeeper:
Elosztott vezérlőrendszer, amely az elosztott alkalmazásokhoz szükséges lock-ok kezelését támogatja
Hive:
Elosztott adattárház, amely a HDFS-ben tárolt adatokra épülő SQL alapú lekérdezéseket képes végrehajtani (amelyeket párhuzamos MapReduce jobokba képez le)
Chukwa:
Elosztott adatgyűjtő és analizáló rendszer
Mahout
Egy igen érdekes Hadoop-ra épülő fejlesztés, amely a napokban jutott el a 0.2-es verzióig, az Apache Lucene alprojektje, a Mahout.
A Mahout egy (a Hadoopnak köszönhetően) masszívan skálázható, gépi tanulási algoritmusokat párhuzamosított MapReduce paradigmával megvalósító programkönyvtár. Az adatbányászati algoritmusok közismerten nagy teljesítményigénye miatt a masszív párhuzamos elemzés lehetősége TB-os nagyságrendű adatmennyiségek esetén egy komoly pont az Apache-nak. A Mahoutban elérhető algoritmusok listája kattintásra nyílik.
Itt olvashattok még Bayes fiterekről, osztályozásról, klaszterezésről és egyéb nyalánkságokról Mahoutban, az IBM előadásában.
HadoopDB
Egy másik érdekes fejlesztés, ami a korábban már e blogban is citált Daniel Abadi diákjai nevéhez fűződik, a HadoopDB.
Az elosztott adatbáziskezelő PostgreSQL, Hadoop, Hive és saját fejlesztésű interface-ekből álló OpenSource stackből építkezik. Még beletömködtek egy katalogizáló modult, egy adatbetöltőt és egy query interface-t, amely az inputként kapott MapReduce és SQL lekérdezéseket részben Hadoophoz, részben az egyes shared-nothing clusterben futó node-okon ülő PostgreSQL szerverekhez irányítja.
Jelenleg dolgoznak a konnektorokon különböző DBMS-ekhez, pl. MonetDB-hez is, így ezeket alkalmazva majdan igazán hatékony, oszlop alapú OpenSource MPP-t kaphatunk egyszer.
Persze ez még erősen fejlesztés alatt álló projekt, senki ne számítson a Vertica-hoz (aminek a C-Store-ját többek közt Abadi fejlesztette) hasonló performanciamutatókra,
de reméljük hosszútávon stabil, használható rendszerré növi ki magát.
Abadi blogpostját korábban a HWSW is leközölte, a cikket itt olvashatjátok, benne az architektúradiagrammal.
Ajánlott bejegyzések:




A bejegyzés trackback címe:
Kommentek:
A hozzászólások a vonatkozó jogszabályok értelmében felhasználói tartalomnak minősülnek, értük a szolgáltatás technikai üzemeltetője semmilyen felelősséget nem vállal, azokat nem ellenőrzi. Kifogás esetén forduljon a blog szerkesztőjéhez. Részletek a Felhasználási feltételekben és az adatvédelmi tájékoztatóban.
Feedek
- RSS 2.0
bejegyzések, kommentek - Atom
bejegyzések, kommentek